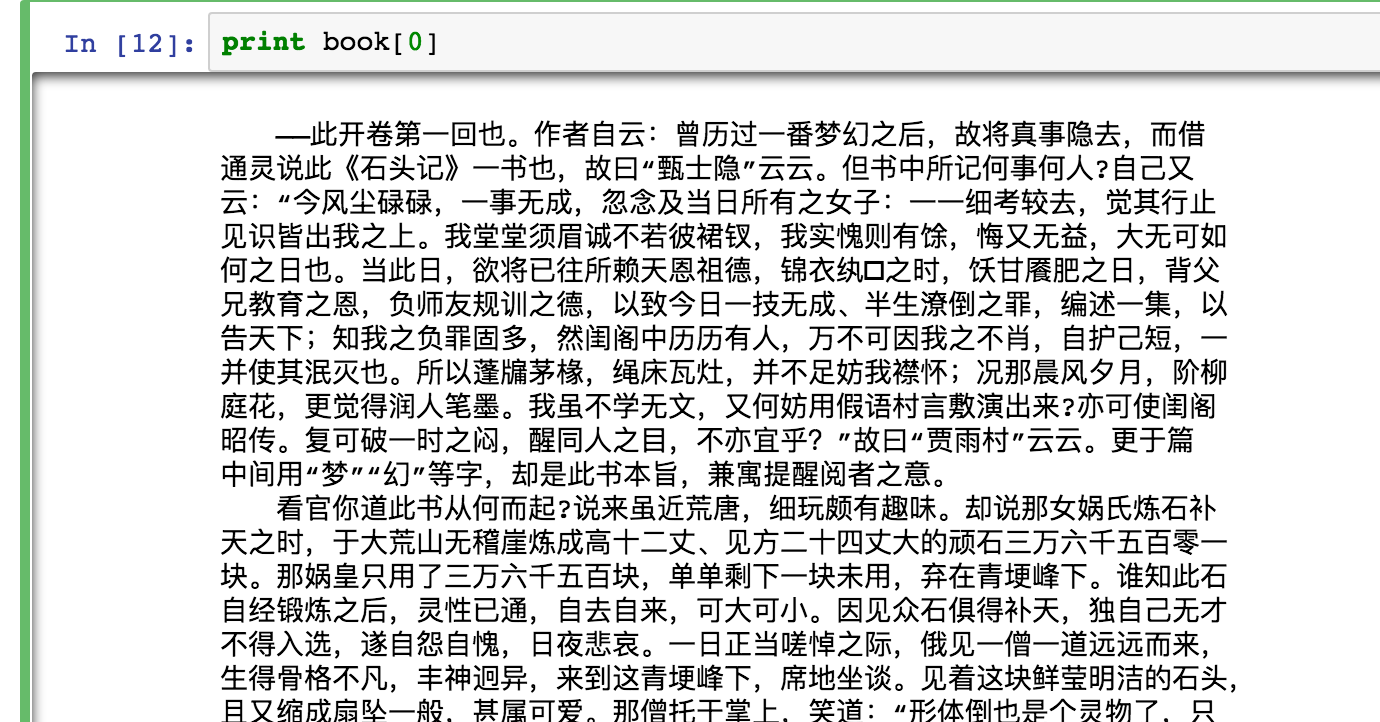
import urllib import urllib2 import re from bs4 import BeautifulSoup as bs
book = [] for i inrange(120): print("处理第{}回...".format(i+1)) if i+1<10: url = "http://www.purepen.com/hlm/00{}.htm".format(i+1) elif i+1 < 100: url = "http://www.purepen.com/hlm/0{}.htm".format(i+1) else: url = "http://www.purepen.com/hlm/{}.htm".format(i+1) request = urllib2.Request(url) response = urllib2.urlopen(request) bsObj = bs(response.read().decode('gb18030')) #注意原网页的codec是哪一种 chapter = bsObj.table.font.contents[0] book.append(chapter)123456789101112131415161718192021
下面是结果:
之后把全文存进一个txt文件:
1 2 3 4 5 6
withopen('红楼梦.txt', 'w') as f: f.write(codecs.BOM_UTF8) for chap in book: s = chap.encode('utf-8').strip() f.write("".join(s.split())) f.write('\n')123456
数据ready,可以开始进行处理了
处理:
直接上代码: 一、导入各种需要的包
1 2 3 4 5 6 7 8 9 10 11 12
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D # 因为后面会用到3d作图 import operator # 下面是机器学习包 from sklearn.cross_validation import train_test_split from sklearn.grid_search import GridSearchCV from sklearn.svm import SVC from sklearn.metrics import classification_report from sklearn.decomposition import PCA # Jieba import jieba123456789101112
二、读取文件并分词
1 2 3 4 5 6 7 8 9
withopen('红楼梦.txt') as f: all_chaps = [chap.decode('utf8') for chap in f.readlines()]
# 给整本书分词 dictionary = [] for i inrange(120): print"处理第{}回".format(i+1) words = list(jieba.cut(all_chaps[i])) dictionary.append(words)123456789
三、Flatten数组 (中文是’摊平’? 哈哈)
1 2
tmp = [item for sublist in dictionary for item in sublist] # 摊平 dictionary = tmp12
四、 给每一回贴上标签
1 2 3 4 5 6 7 8 9
# 给每一回贴上标签 for i inrange(120): if i < 80: all_chaps[i] = [all_chaps[i],'1'] else: all_chaps[i] = [all_chaps[i],'0']
content = [row[0] for row in all_chaps] label = [row[1] for row in all_chaps]123456789
# 找出每一回均有出现的词 from progressbar import ProgressBar # 显示进度 pbar =ProgressBar()
wordineverychap = [] length = len(dictionary) print"共有{}个词".format(length) for word in pbar(dictionary): n = 0 for text in content: if word in text: n+=1 if n==120: wordineverychap.append(word)1234567891011121314
withopen('xuci.txt') as f: xuci = [word.decode('utf8').strip() for word in f.readlines()] for word in xuci: if word notin wordineverychap: wordineverychap.append(word)12345
七、过滤重复的词语,并去掉标点符号
1 2 3 4
selected_words = list(set(wordineverychap)) # 人工处理, 删除标点符号 for w in selected_words: print w1234
计算结果是一共有125个词语
八、给每个词语计数 并 排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
wordT = [] countT = [] table = {}
chapNo = 1 for chap in content: sub_table = {} for word in uw: sub_table[word.decode('utf8')] = chap.count(word.decode('utf8')) table[chapNo] = sub_table chapNo+=1
import operator table_sorted = []
for idx in table: sub_table_sorted = sorted(table[idx].items(),key=operator.itemgetter(1),reverse=True) table_sorted.append(sub_table_sorted)123456789101112131415161718
九、把数据存在csv里,以免不小心关掉程序后不用重新计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
# 任务:把数据存到csv里 import unicodecsv as csv
# 写入第一行和第一列 f1 = open('cipin.csv', 'w+') writer = csv.writer(f1, encoding='utf8', delimiter=',') first_row = [''] # A1留空 for i inrange(120): first_row.append('第{}回'.format(i+1)) writer.writerow(first_row)
for word in selected_words: row = [word] for i inrange(120): row.append(table[i+1][word.decode('utf8')]) writer.writerow(row)
f1.close()12345678910111213141516171819
十、把数据向量化
1 2 3 4 5 6 7 8 9 10
# 任务:把数据向量化
all_vectors = []
for i inrange(120): chap_vector = [] for word in selected_words: chap_vector.append(table[i+1][word.decode('utf8')]) all_vectors.append(chap_vector) 12345678910
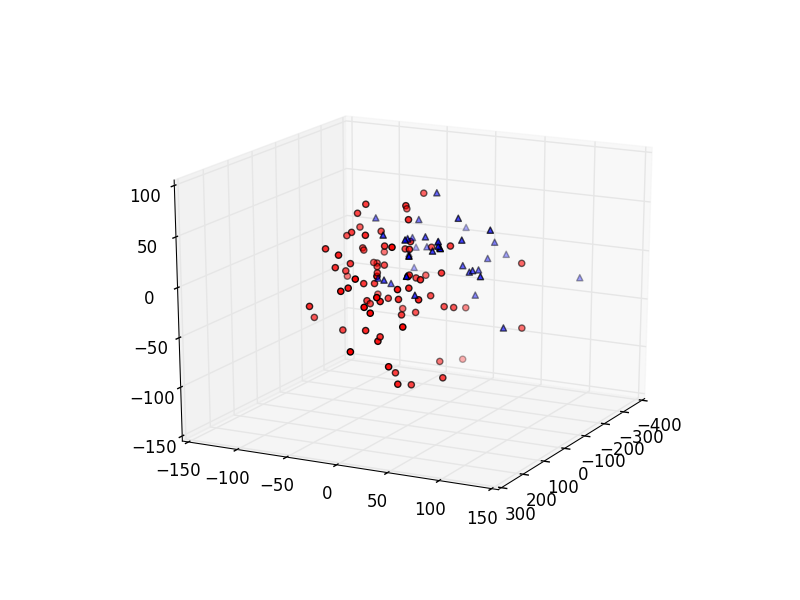
#设置PCA的目标维数并创建一个model pca = PCA(n_components=3) #Feed我们的向量,进行训练 pca.fit(all_vectors) #取得目标向量 z = pca.fit_transform(all_vectors) #取得前八十回的向量 xs_a = [row[0] for row in z[:80]] ys_a = [row[1] for row in z[:80]] zs_a = [row[2] for row in z[:80]] #取得后四十回的向量 xs_b = [row[0] for row in z[-40:]] ys_b = [row[1] for row in z[-40:]] zs_b = [row[2] for row in z[-40:]]
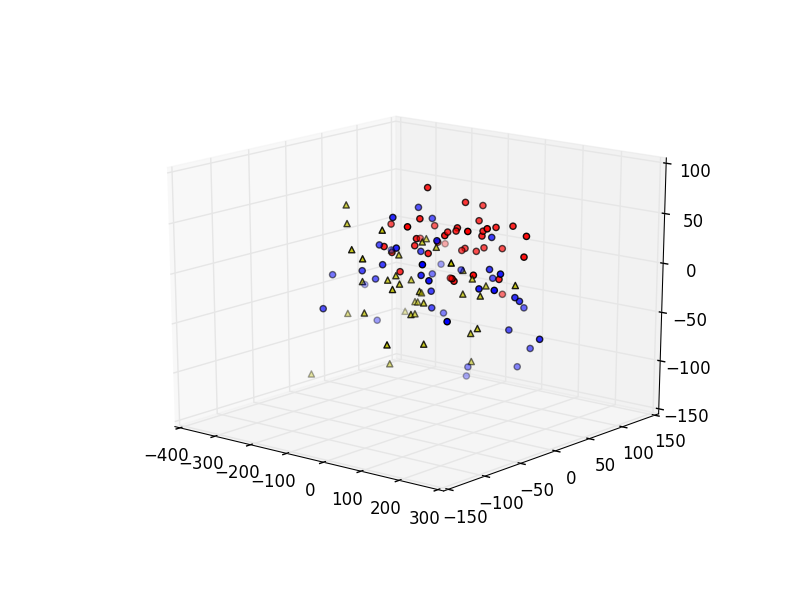
#前四十回 xs_a = [row[0] for row in z[:40]] ys_a = [row[1] for row in z[:40]] zs_a = [row[2] for row in z[:40]] #中间四十回 xs_b = [row[0] for row in z[40:80]] ys_b = [row[1] for row in z[40:80]] zs_b = [row[2] for row in z[40:80]] #最后四十回 xs_c = [row[0] for row in z[-40:]] ys_c = [row[1] for row in z[-40:]] zs_c = [row[2] for row in z[-40:]]