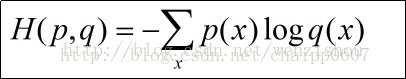【数据可视化】电视产品精准营销推荐
获奖经历:
2017年4月:美国大学生数学建模竞赛二等奖
2017年11月:数学建模竞赛国家一等奖
2017年11月:数学竞赛国家二等奖
2018年4月:美国大学生数学建模竞赛二等奖
2018年5月:泰迪杯数据挖掘竞赛国家二等家
兴趣爱好:羽毛球,读书
个人生活照:(1-2张)

一、实验目的
1、实验背景
本实验项目来自于第六届泰迪杯数据挖掘竞赛,共包含用户观看信息和电视产品信息两组数据,通过对数据进行处理,实现产品的精准营销推荐,并将并将结果进行可视化展示。
2、实验目的
基于电视产品及用户信息数据对产品进行精准营销推荐,并将结果进行可视化展示。主要实现以下两个目的:
(1)产品的精准营销推荐
根据用户观看记录信息数据,分析用户的收视偏好,并给出电视产品的营销推荐方案。
(2)相似偏好用户的产品打包推荐
为了更好地为用户服务,扩大营销范围,利用数据对相似偏好的用户进行分类(用户标签),对产品进行分类打包(产品标签),并给出营销推荐方案。
3、实验内容与要求
(1)对数据进行处理,并根据用户的收视信息对用户偏好进行分析,将分析结果用图像进行表示。
(2)整理产品信息,重新对产品分类,将产品类别通过可视化方式表达。
(3)利用推荐算法和聚类算法对产品进行推荐,将具体过程进行展示。
(4)对结果进行分析,得出精准的营销推荐方案以及有效的可视化展示结果。
4、实验所用工具
l Excle
利用其中的统计和编程工具对数据进行处理和分析
l Echarts
含有多类图像,在没有可视化思路时,可以利用它寻找灵感,代码易改易实施
l Rstudio
其中的ggplot/echarts绘画包中图像丰富,语句简单
l Microsoft Visio
适合流程图说明图的绘制,简单易操作
二、实验过程
1、数据介绍
数据来源于泰迪杯数据挖掘竞赛官网,包括用户收看电视的信息记录和产品的各项参数。
用户信息:

图1.用户信息数据
产品信息:
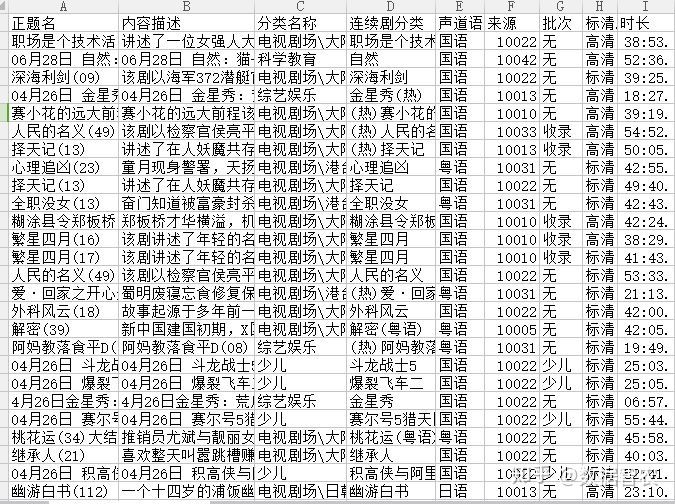
图2.产品信息数据
2、数据清洗
(1)删除重复内容,以及错误信息:对数据进行初步整理,删掉无效数据
(2)提取产品标签 =TEXT(E2,”h:mm”)转化时间
=TEXT(H2-G2,”[m]”)求时间差
用数据透视表求频数
(3)提取用户标签,分析用户偏好:将产品类别与用户信息偏好类别进行统一,在用户信息表中添加偏好类型、是否高清、时间段、观看频数、时长标签
3、清洗后数据
用户信息:
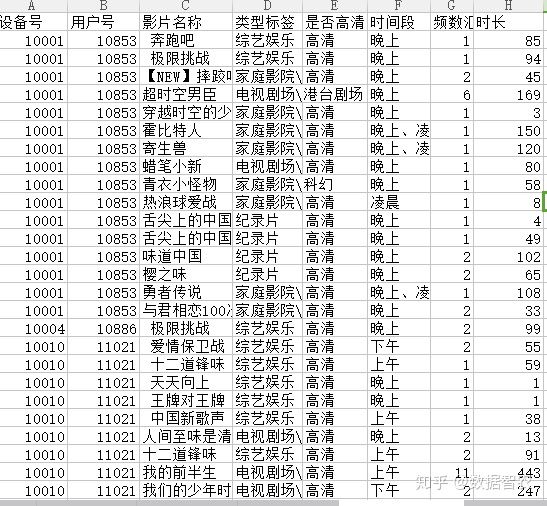
产品信息:

图3.数据清洗后数据
三、可视化展示及结果
1.旭日图
主题:对产品类别进行展示(使用工具:Echarts )
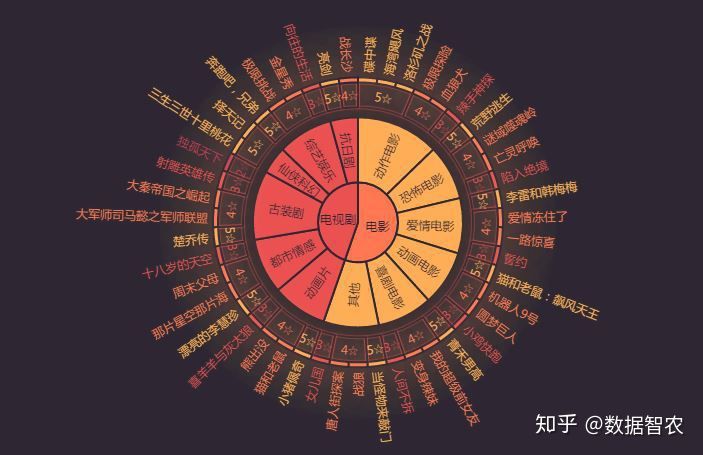
图4.产品类别图
由图可知产品主要分为两类:电影和电视剧,其中电影又分为:动作电影、恐怖电影、爱情电影、动画电影、喜剧电影与其他;
电视剧又分为:抗日剧、古装剧、综艺娱乐、仙侠科幻、都市情感与动画片;
电影类产品中动作类电影产品最多;其中产品“碟中谍”热度最高
电视剧中古装剧产品最多,其中“独孤天下”热度最高
2.嵌套环形图
主题:以10853号用户为例,对用户偏好进行展示(使用工具:Echarts)

图5.用户偏好
10853用户喜欢四类产品类型:家庭影院、纪录片、综艺娱乐、大陆剧场,其中最喜欢观看家庭影院类型产品,在众多节目中喜欢观看舌尖上的中国和味道中国等美食节目。
3.碎石图
主题:针对本文所研究的问题,需要对影视产品进行打包,进而以产品包为单位向用户进行推荐。为此我们引入K-means 聚类分析理论,将同种类型的产品进行打包,此时问题重点是探索所推荐的产品包中影视产品的最佳数量和产品包的最终分类结果。
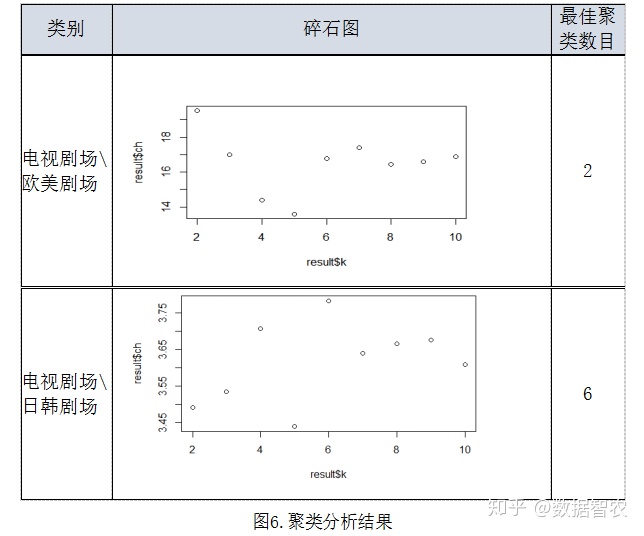
由图可知,最佳聚类数目分别为2和6,电视剧场/欧美剧场分类中还可以将产品细分为2类,大陆剧场/日韩剧场这个分类中则可以将产品细化为6类。
\4. 折线图
对产品进行打包后,采用推荐算法对产品进行推荐。本项目采用协同过滤推荐算法、热点推荐算法和随机推荐算法三种推荐方式。为了实现产品的个性化推荐,自定义推荐产品包数目,通过十折交叉验证检测准确率和召回率。
两个主题:
(1)通过准确率和召回率对三种推荐方式进行比较。
(2)选择合适的产品包推荐数目。
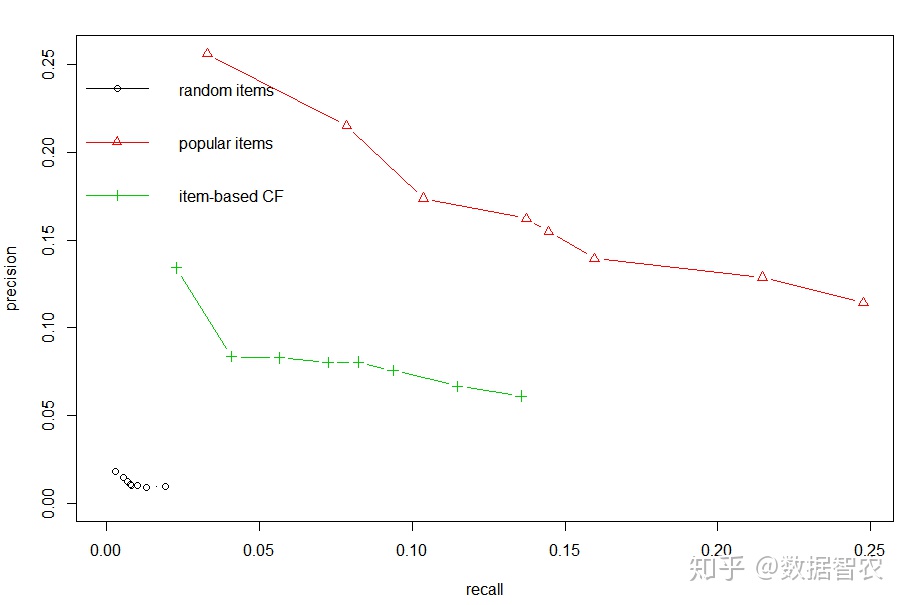
图7.三种推荐方式对比
由图知,热点推荐模型和协同过滤推荐模型的准确度和召回率均远远高于随机推荐,说明热点推荐模型和协同过滤模型对于重要价值用户的个性化推荐效果显著。其中热点推荐效模型效果好于协同过滤推荐,并且,热点推荐和协同过滤推荐在产品包推荐数目为 1 时同时达到精准率最大值,同时也是召回率最小值。当推荐打包数为 20 个时,协同过滤推荐和热点推荐的召回率均达到最大值,但此时精准率达到最小值。
5.气泡图
因为精准率与召回率二者评价模型的标准均为越接近于1越好,但是在保证精准率的前提下,召回率就难以得到保障,同样地在保障召回率的前提下,精准率就不能得到保障,因此,本文根据精准率和召回率计算得到平衡F分数(F1 的值,它可以同时兼顾模型的精准率和召回率,如下:

两个主题:
(1)通过可视化寻找三类推荐算法用户最佳推荐个数,根据最佳推荐个数为用户推荐产品
(2)对三类推荐算法进行比较,选择平衡分数最高的推荐算法进行推荐。
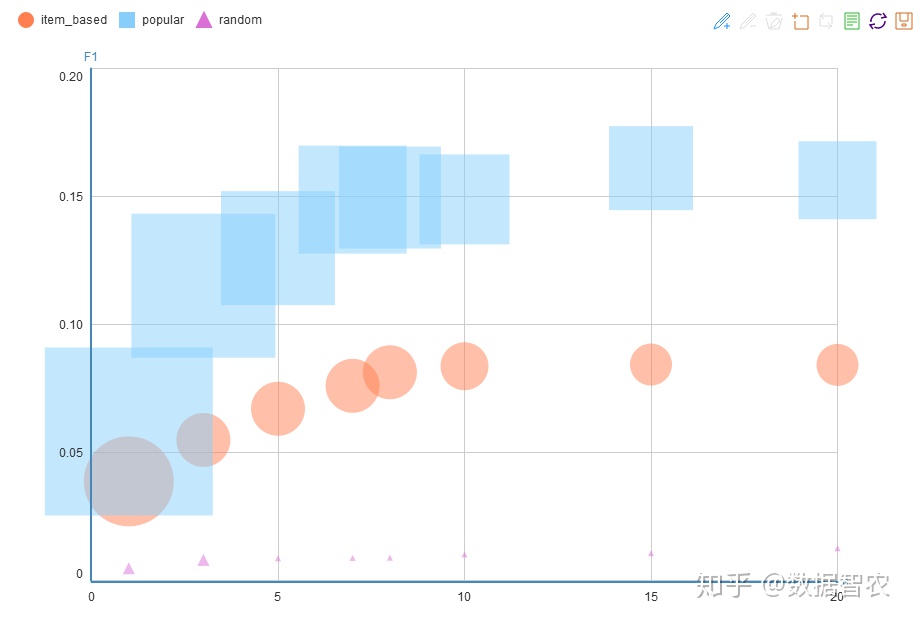
图7.平衡分数
由图可知热点推荐模型形状最大,其平衡分数最高,协同过滤推荐其次,随机推荐最低
6.产品介绍图
主题:对协同过滤推荐算法的具体过程及原理进行介绍(使用工具:Microsoft Visio)
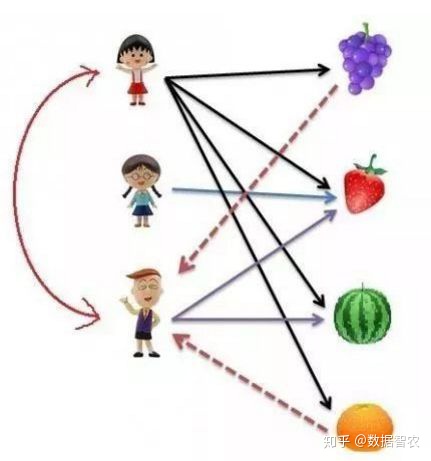
基于用户的协同过滤算法:我们知道樱桃小丸子喜欢葡萄、草莓、西瓜和橘子,而我们通过某种方法了解到小丸子和花伦有相似的喜好,所以我们会把小丸子喜欢的而花伦还未选择的水果(葡萄和橘子)推荐给花伦。

图9.基于物品的协同过滤算法
基于物品的协同过滤算法:给用户推荐那些和他们之前喜欢的物品相似的物品。比如,我们知道樱桃小丸子和小玉都喜欢葡萄和西瓜,那么我们就认为葡萄和西瓜有较高的相似度,在花伦选择了西瓜的情况下,我们会把葡萄推荐给花伦。
\7. 漏斗图
主题:以10853号用户为例,对推荐结果进行展示(使用工具:Echarts )
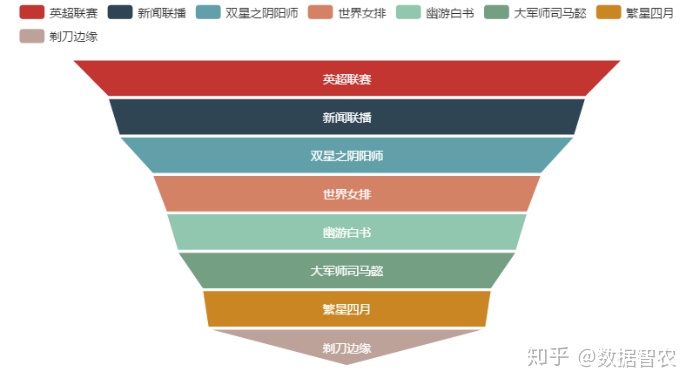
图10.推荐结果展示
根据推荐算法进行分析,共对用户10853推荐8个产品。其中英超联赛推荐指数最高,新闻联播次之。
四、图表制作
1、旭日图制作
步骤:
(1)对一级指标“电影/电视剧”进行修改,将data第一个name标签内容替换。
(2)对二级指标“动作电影/喜剧电影等”修改,将第一个children类下的name标签替换。
(3)对三级指标产品名称如“摔跤吧爸爸”等进行修改,将第二个children类下的name标签内容替换。
(4)若多增加标签,则增添children[{name:’’},{name:’’}]
程序:

图11.旭日图程序
2.嵌套环形图制作
步骤:
(1)对图像标题进行修改
(2)对图像内容进行替换,并将各部分占比进行修改
程序:
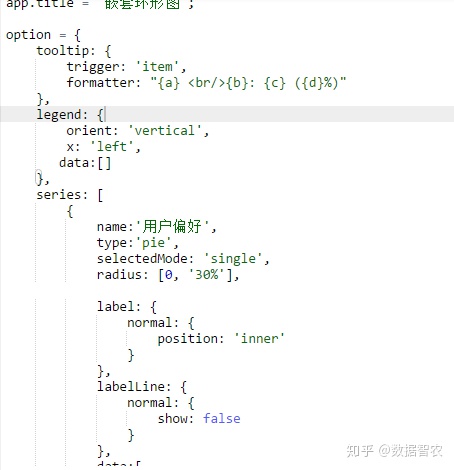

图12.嵌套环形图程序
3.碎石图制作
步骤:
(1)对于产品内容进行中文分词,并构成 dtm 矩阵。
(2)基于dtm 矩阵,采用 Kmeans 均值聚类计算产品数目大于30的类别之间的距离,采用碎石图,得到每一个一级标签分类的最佳聚类数
形成的dtm矩阵如下:
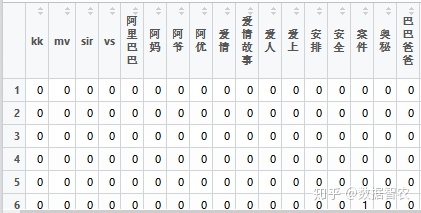
图13.DTM矩阵
程序:

4.折线图制作
步骤:
(1)采用三种推荐算法,基于用户偏好进行产品推荐。
(2)通过十折交叉验证对推荐结果进行验证,得到不同推荐产品包数目的结果准确率与召回率,这里探究自定义产品包数目为(1,3,5,7, 8,10,15,20)时的准确率与召回率。
(3)对三种推荐算法在不同推荐情况下的准确率与召回率进行可视化表达,探索最优算法
程序:

5.气泡图制作
步骤:
(1)导入平衡分数计算公式
(2)对三类推荐算法在不同推荐情况下的平衡分数进行可视化表达,对折线图、气泡图两种表达方式进行对比,最终选择气泡图,因为其可以动态的表示每点数据情况。
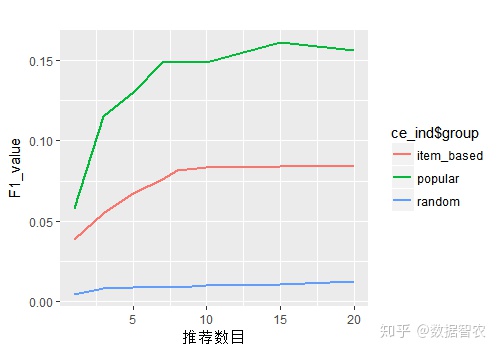
图14.推荐算法比较
程序:

6.产品介绍图制作
步骤:
(1)使用visio2003创建一个新文件
(2)选择对应形状拖动进绘画板
(3)文件保存,发布

图15.visio绘图
7.漏斗图制作
步骤:
1.对legend数据框中data的内容进行修改,对图例内容进行替换。
2.对图中数据进行替换,并对各数据占比进行修改,数据皆为百分制
程序:


图16.漏斗图程序