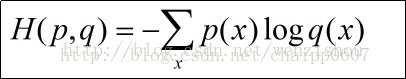决策树中结点的特征选择方法
一、信息增益
信息增益用在ID3决策树中,信息增益是依据熵的变化值来决定的值。
熵:随机变量不确定性大小的度量。熵越大,变量的不确定性就越大。
熵的公式表示:
X的概率分布为P(x=xi) = pi, i=1,2,3…(x可能的取值),随机变量X熵为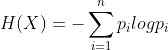
条件熵:H(Y|X)表示在随机变量X的条件下随机变量Y的不确定性。
在决策树中,Y即是数据集,X即是某个特征,即条件熵就是数据集在特征A划分条件下的熵。
信息增益:数据集D的熵H(D)与特征A给定条件下D的条件熵H(D|A)之差。g(D|A)=H(D)-H(D|A)
因此根据信息增益决策划分节点时特征选择方法是:对训练数据集D,计算其每隔特征的信息增益,并比较它们的大小,选择信息增益最大的特征。
二、信息增益比
以信息增益作为划分数据集的特征,存在偏向于选择去取值较多的特征的问题,这时候可以使用信息增益比对这一问题进行修正。C4.5决策树正是基于信息增益比进行特征的选择进行结点的分割。
信息增益比定义:特征A对于训练集D的信息增益比定义为信息增益g(D|A)与数据集D关于特征A的值得熵之比。
公式定义:
关于为什么信息增益比可以修正信息增益存在偏向去选择取值较多的特征的问题,可以认为当一个特征取值特别多时,会分出很多个子结点,当数据集不是很大时,每个子结点只能有很少的数据,大数定律满足条件性更差,不能体现整体数据集的分布,从而使得不确定性减小,比如这个特征有N个取值,且数据集恰好有N个例子,从而每个结点只有一个数据,从而每点的熵均为0,从而加起来也为0,从而信息增益最大。然而,当数据集十分大足够大时,就不会存在这种问题了。
三、基尼指数(Gini)
CART树分为回归树和分类树,CART分类树结点选择特征进行分裂时选择特征的方法就是基尼指数。
分类问题中,假设有K个类,样本点属于第k类的概率为
基尼指数Gini(D)表示集合D的不确定性,基尼指数Gini(D,A)表示经A=a分割后集合D的不确定性,基尼指数越大,样本集合的不确定性也就越大,与熵类似。