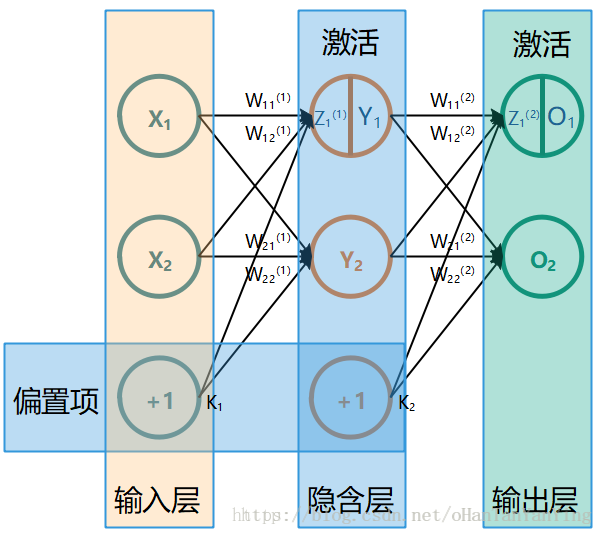
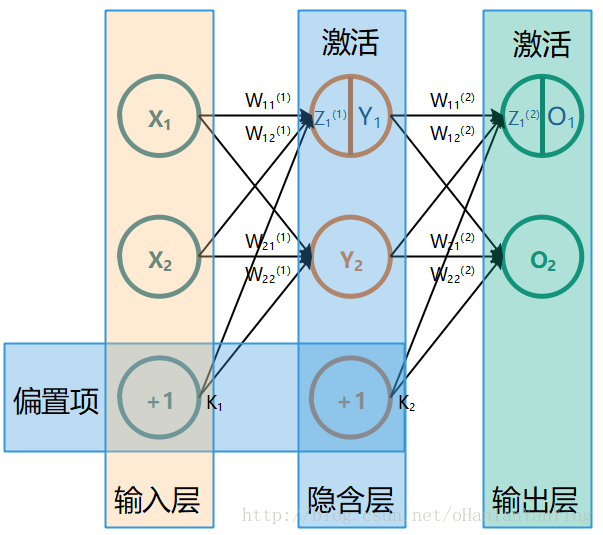
void node::initNode(int num) { W = new double[num]; srand((unsigned)time(NULL)); for (size_t i = 0; i < num; i++)//给权值赋一个随机值 { W[i]= (rand() % 100)/(double)100; } }
node::~node() { if (W!=NULL) { delete[]W; } }
//网络类,描述神经网络的结构并实现前向传播以及后向传播 class net { public: node inlayer[IPNNUM]; //输入层 node hidlayer[HDNNUM];//隐含层 node outlayer[OPNNUM];//输出层
class node: #结点类,用以构成网络 def __init__(self,connectNum=0): self.value=0 #数值,存储结点最后的状态,对应到文章示例为X1,Y1等值 self.W = (2*np.random.random_sample(connectNum)-1)*0.01
class net: #网络类,描述神经网络的结构并实现前向传播以及后向传播 def __init__(self): #初始化函数,用于初始化各层间节点和偏置项权重 #输入层结点 self.inlayer=[node(HDNNUM)]; for obj in range(1, IPNNUM): self.inlayer.append(node(HDNNUM)) #隐含层结点 self.hidlayer=[node(OPNNUM)]; for obj in range(1, HDNNUM): self.hidlayer.append(node(OPNNUM)) #输出层结点 self.outlayer=[node(0)]; for obj in range(1, OPNNUM): self.outlayer=[node(0)]
def getLoss(self): #损失函数 loss=0 for num in range(0, OPNNUM): loss+=pow(self.O[num] -self.Tg[num],2) return loss/OPNNUM
def forwardPropagation(self,input): #前向传播 for i in range(0, IPNNUM): #输入层节点赋值 self.inlayer[i].value = input[i] for hNNum in range(0,HDNNUM): #算出隐含层结点的值 z = 0 for iNNum in range(0,IPNNUM): z+=self.inlayer[iNNum].value*self.inlayer[iNNum].W[hNNum] #加上偏置项 z+= self.k1 self.hidlayer[hNNum].value = self.sigmoid(z) for oNNum in range(0,OPNNUM): #算出输出层结点的值 z = 0 for hNNum in range(0,HDNNUM): z += self.hidlayer[hNNum].value* self.hidlayer[hNNum].W[oNNum] z += self.k2 self.O[oNNum] = self.sigmoid(z)
def backPropagation(self,T): #反向传播,这里为了公式好看一点多写了一些变量作为中间值 for num in range(0, OPNNUM): self.Tg[num] = T[num] for iNNum in range(0,IPNNUM): #更新输入层权重 for hNNum in range(0,HDNNUM): y = self.hidlayer[hNNum].value loss = 0 for oNNum in range(0, OPNNUM): loss+=(self.O[oNNum] - self.Tg[oNNum])*self.O[oNNum] * (1 - self.O[oNNum])*self.hidlayer[hNNum].W[oNNum] self.inlayer[iNNum].W[hNNum] -= self.yita*loss*y*(1- y)*self.inlayer[iNNum].value for hNNum in range(0,HDNNUM): #更新隐含层权重 for oNNum in range(0,OPNNUM): self.hidlayer[hNNum].W[oNNum]-= self.yita*(self.O[oNNum] - self.Tg[oNNum])*self.O[oNNum]*\ (1- self.O[oNNum])*self.hidlayer[hNNum].value
def printresual(self,trainingTimes): #信息打印 loss = self.getLoss() print("训练次数:", trainingTimes) print("loss",loss) for oNNum in range(0,OPNNUM): print("输出",oNNum,":",self.O[oNNum])
def forward(self, input): #定义该神经网络的向前传播函数,该函数必须定义,一旦定义成功,向后传播函数也会自动生成 x = torch.nn.functional.sigmoid(self.intohid_layer(input)) #输入input在输入层经过经过加权和与激活函数后到达隐含层 x = torch.nn.functional.sigmoid(self.hidtoout_layer(x)) #类似上面 return x
for t in range(0,5000): optimizer.zero_grad() #清空节点值 out=mnet(input) #前向传播 loss = loss_fn(out,target) #损失计算 loss.backward() #后向传播 optimizer.step() #更新权值 if (t%1000==0): print(out)
def forward(self, input): #定义该神经网络的向前传播函数,该函数必须定义,一旦定义成功,向后传播函数也会自动生成 x = torch.nn.functional.sigmoid(self.intohid_layer(input)) #输入input在输入层经过经过加权和与激活函数后到达隐含层 x = torch.nn.functional.sigmoid(self.hidtoout_layer(x)) #类似上面 return x
for t in range(0,5000): optimizer.zero_grad() #清空节点值 out=mnet(input) #前向传播 loss = loss_fn(out,target) #损失计算 loss.backward() #后向传播 optimizer.step() #更新权值 if (t%1000==0): print(out)